2.3-b 강화학습의 발전
강화학습(Reinforcement Learning, RL)은 에이전트가 환경과의 상호작용을 통해 의사결정을 학습하는 머신러닝 패러다임입니다. 지도학습이 레이블이 지정된 데이터에서 학습하는 것과 달리, 강화학습은 시행착오(trial-and-error)를 기반으로 하여 행동을 탐색하고, 누적 보상을 최대화하는 정책(policy)을 학습합니다. 강화학습은 마르코프 결정 과정(Markov Decision Process, MDP)을 통해 수학적으로 공식화되며, 상태(state)를 관찰한 에이전트가 행동(action)을 취한 후 환경으로부터 보상(reward)과 새로운 상태를 받아 지속적으로 정책을 개선하는 구조입니다.
이 글에서는 강화학습의 초기 개념부터 최근 게임 분야의 탁월한 성과에 이르는 발전 과정을 연대기적으로 살펴보겠습니다. 가치 함수(value function), 시간차 학습(Temporal Difference Learning), Q-러닝(Q-Learning), 정책 최적화(Policy Optimization) 등의 기술적 개념을 쉽게 설명하고, 알고리즘의 진화를 통해 실제 산업 분야(로봇, 게임, 금융, 의료, 자율 시스템 등)에 적용된 사례들을 다룹니다. 또한 강화학습 분야의 현존하는 도전 과제와 연구 동향을 소개합니다.

1. 강화학습의 출현
강화학습의 뿌리는 행동주의 심리학과 최적 제어 이론에서 찾을 수 있습니다. 심리학자 손다이크의 '효과의 법칙(Law of Effect)'과 스키너의 동물 실험을 통해 보상을 통한 행동 강화의 원리가 탐구되었습니다. 수학적으로는 1950-60년대 리처드 벨만이 최적 제어와 동적 프로그래밍(dynamic programming)을 연구하면서 벨만 방정식(Bellman Equation)을 도입하여 순차적 의사결정 문제의 최적 정책을 구하는 방법이 발전했습니다.

벨만 방정식(Bellman Equation) 이란?1950~1960년대, 리처드 벨만(Richard Bellman)은 순차적으로 결정을 내려야 하는 문제, 즉 "지금 무엇을 해야 가장 좋은 결과를 얻을 수 있을까?"를 수학적으로 풀어내기 위한 방정식을 만들었습니다.벨만 방정식은 "현재의 가치 = 지금 얻는 보상 + 앞으로 최선을 다했을 때 얻을 수 있는 기대 가치"를 의미합니다.수식은 다음과 같습니다.  이걸 쉽게 풀어보면:
"지금 행동으로 얻는 보상"과 "앞으로 최선을 다했을 때 얻을 미래 보상 (약간 할인해서 계산)"을 더한 것입니다. 벨만 방정식(Bellman Equation) 상세설명 |
1980년대 중반에는 리처드 서튼의 시간차 학습(TD Learning)이 등장하며 중요한 전환점이 되었습니다. TD 학습은 모델이 필요 없는(model-free) 가치 함수 학습 방법으로, 몬테카를로 방법과 동적 프로그래밍을 결합하여 데이터 효율성을 높였습니다.

시간차 학습(TD Learning)이란?시간차 학습(Temporal Difference Learning, TD Learning)은 "경험을 통해 미래를 예측하는 방법"으로 "조금 앞선 예측을, 실제 결과를 보고 계속 수정하는 방법"입니다. 이 방법은 실시간으로 학습하고, 최종 결과를 기다리지 않고도 빠르게 경험을 활용할 수 있도록 해주며, Q-러닝 같은 강력한 알고리즘들의 기반이 되었습니다.시간차 학습의 기본 아이디어
공식으로 간단히 표현하면: TD Error = (현재 보상 + γ × 다음 상태의 예측) − 현재 상태의 예측 여기서 γ는 미래 보상을 얼마나 중요하게 생각할지를 결정하는 수치(감가율, discount factor)입니다. 시간차 학습(TD Learning) 상세설명 |
이어 1989년 크리스 왓킨스가 개발한 Q-러닝은 상태-행동 가치 함수(state-action value function, Q-value)를 직접 학습하는 모델 프리 오프폴리시(model-free, off-policy) 알고리즘으로, 모델 없이도 최적의 행동 전략을 학습할 수 있는 혁신적인 방식이었습니다.

Q-러닝이란?Q-러닝은 경험을 통해 스스로 문제를 해결하는 방법을 배우는 알고리즘입니다. "어떤 상황(State)에서 어떤 행동(Action)을 선택하면 보상을 가장 많이 받을 수 있을까?"를 스스로 탐색하고 학습하는 방식입니다.이때 Q-러닝은 Q값(Quality Value)이라는 숫자를 이용합니다. 이 Q값은 "현재 상태에서 어떤 행동을 했을 때 기대할 수 있는 보상의 총합"을 의미합니다. Q-러닝의 작동 방식Q-러닝은 다음과 같은 과정을 반복하면서 학습합니다:
Q-러닝은 강화학습을 이해하는 데 기본이 되는 개념입니다. 이 원리를 바탕으로 이후에 더 복잡한 알고리즘(Deep Q-Learning 등)이 개발되었습니다. Q-러닝(Q-Learning) 상세설명 |
1990년대 초 제럴드 테소로(Gerald Tesauro)가 '시간차 학습(TD Learning)'을 활용하여 개발한 'TD-Gammon'이라는 프로그램을 통해 강화학습의 가능성이 증명되었습니다.
TD-Gammon은 주사위를 굴려 말을 이동시키는 전략 게임 "백개먼(Backgammon)"을 두는 인공지능 프로그램입니다. 백개먼은 어느 정도 운이 개입되지만 전략적인 선택도 매우 중요한 게임으로 TD-Gammon은 스스로 게임을 반복하면서 점점 실력을 키워 당시 세계 최고의 백개먼 플레이어들과 대등하게 경쟁할 수준에 도달했습니다..
강화학습의 가능성을 증명한 TD-Gammon1990년대 초, 강화학습의 잠재력을 세상에 알린 중요한 사건으로 'TD-Gammon'이라는 프로그램이 개발되었습니다. 이 프로그램은 제럴드 테소로(Gerald Tesauro)가 개발했으며, 강화학습 알고리즘 중 하나인 '시간차 학습(TD Learning)'을 활용해 만들어졌습니다.TD-Gammon은 보드게임 "백개먼(Backgammon)"을 두는 인공지능 프로그램입니다. 백개먼은 주사위를 굴려 말을 이동시키는 전략 게임으로, 어느 정도 운이 개입되지만 전략적인 선택도 매우 중요한 게임입니다. 기존에는 백개먼에서 사람을 이길 수 있는 프로그램을 만드는 것이 어려운 일로 여겨졌습니다. 하지만 TD-Gammon은 사람의 수를 가르쳐주지 않고, 스스로 게임을 반복하면서 점점 실력을 키워갔습니다. TD-Gammon 학습방법
TD-Gammon의 주요성과
TD-Gammon의 의미
|
2. 정책 경사법과 액터-크리틱 방법론의 등장
초기 강화학습 알고리즘은 주로 가치 기반(value-based)으로, 가치 함수에서 간접적으로 정책을 유도했습니다. 1992년 로널드 윌리엄스의 REINFORCE 알고리즘을 시작으로 정책 경사법(policy gradient)이 발전하여, 정책을 직접 학습할 수 있게 되었습니다.
정책 경사법은 간단히 말해, "좋은 행동을 더 자주 하도록 정책(policy)을 조금씩 조정하는 방법"입니다. 여기서 정책이란, 주어진 상황에서 어떤 행동을 할지 결정하는 방법(또는 확률 분포)을 뜻합니다.
- 정책(Policy): 어떤 상황(state)에서 어떤 행동(action)을 할 확률을 정해주는 것
- 경사(Gradient): 현재 정책을 조금 더 좋은 방향으로 바꾸기 위해 필요한 조정 방향
정책 경사법은 정책을 직접 조정하면서 학습합니다. 좋은 행동을 했을 때는 그 행동을 더 잘하도록 정책을 강화하고, 나쁜 행동을 했을 때는 그 행동을 줄이는 식입니다. 정책 경사법(Policy Gradient) 상세설명

이후 액터-크리틱(actor-critic) 구조가 제안되어 정책 경사법의 성능과 안정성을 높였습니다.
"액터-크리틱(Actor-Critic)" 구조는 강화학습에서 정책 경사법(Policy Gradient)의 성능과 학습 안정성을 높이기 위해 고안된 방법입니다. 쉽게 말해, 행동을 결정하는 주체(Actor)와 그 행동이 얼마나 좋은지 평가하는 주체(Critic)를 따로 분리해서 함께 학습하는 방식입니다.
- Actor는 현재 상태를 보고 행동을 선택합니다.
- 환경(Environment)은 그 행동에 대한 보상(Reward)과 다음 상태를 돌려줍니다.
- Critic은 "이 행동이 정말 좋은 선택이었는가?"를 평가합니다.
- 평가 결과를 바탕으로:
- Actor는 더 좋은 행동을 하도록 정책을 업데이트합니다.
- Critic은 더 정확한 평가를 할 수 있도록 자신의 판단 기준(가치 함수)을 업데이트합니다.
이 과정을 반복하면서 Actor는 더 좋은 행동을 선택하도록 배우고, Critic은 평가를 점점 더 정확하게 합니다.
액터-크리틱 구조는 "행동하는 주체(Actor)"와 "행동을 평가하는 주체(Critic)"가 서로 협력하면서 강화학습을 더 빠르고 안정적으로 만드는 방법입니다. 복잡한 문제를 다룰 때 오늘날 가장 널리 쓰이는 강화학습 구조 중 하나입니다.
액터-크리틱(Actor-Critic) 구조 상세설명

3. 딥러닝과 강화학습의 결합
2010년대에 들어 신경망의 발전으로 강화학습은 획기적인 전환을 맞았습니다. DeepMind의 딥 Q 네트워크(DQN, 2015)는 영상 픽셀 데이터에서 직접 Q값을 학습하여 아타리(Atari) 게임을 인간 수준으로 플레이하는 성과를 냈습니다. 이어서 DDPG, A3C, PPO와 같은 새로운 알고리즘들이 등장하여 연속 행동 공간과 복잡한 문제를 해결할 수 있게 되었습니다.
DeepMind의 딥 Q 네트워크(DQN) 사례배경: 왜 딥러닝과 강화학습을 결합했을까?기존의 Q-러닝은 이론적으로 매우 강력했지만, 복잡한 문제(예: 게임 화면처럼 수많은 입력이 있는 경우)에서는 직접 테이블을 만들어서 모든 상태와 행동의 값을 저장하기 어려웠습니다. 데이터가 너무 많고, 상태가 너무 복잡했기 때문입니다.그래서 DeepMind는 2015년에 "딥 Q 네트워크(DQN)"라는 새로운 방식을 제안했습니다. 이 방법은 Q-러닝에 '딥러닝'을 결합해, 복잡한 입력(예: 게임 화면 이미지)에서도 스스로 좋은 행동을 찾을 수 있도록 했습니다. 딥 Q 네트워크(DQN)의 핵심 아이디어
딥 Q 네트워크(DQN)가 도입한 두 가지 주요 기술
딥 Q 네트워크(DQN)의 성과 및 의의
DQN은 복잡한 환경에서도 사람이 일일이 Q값을 계산해주지 않아도, 딥러닝을 활용해 스스로 최적의 행동을 학습할 수 있게 만든 획기적인 방법이었습니다. 이 성과 덕분에 강화학습이 실제 복잡한 문제에 적용될 수 있는 가능성을 크게 넓혔고, 이후 알파고(AlphaGo) 같은 놀라운 AI 기술들의 발전에도 중요한 밑거름이 되었습니다. |
4. 게임 정복: 알파고에서 알파스타까지
강화학습은 AlphaGo(2016)의 바둑, AlphaZero(2017)의 체스, 쇼기, 그리고 OpenAI Five(2018)의 도타2(Dota 2), AlphaStar(2019)의 스타크래프트2(StarCraft II)에 이르기까지 복잡한 게임에서 초인적인 성과를 이루며 세간의 이목을 집중시켰습니다. 이들은 딥러닝과 몬테카를로 트리 탐색(MCTS), 다중 에이전트 자기 대전 등 혁신적인 방법을 통해 인간 챔피언을 능가했습니다.
AlphaGo (2016) - 바둑 정복
- 기관: DeepMind
- 개요: 강화학습과 심층 신경망을 결합하여, 인간 프로 수준의 바둑 실력을 갖춘 인공지능 개발.
- 핵심 기술:
- 지도학습(Supervised Learning)으로 인간 기보를 먼저 학습
- 그 후 강화학습(Self-Play Reinforcement Learning)으로 스스로 실력을 향상
- 몬테카를로 트리 탐색(MCTS, Monte Carlo Tree Search)과 신경망을 결합해 수를 선택
- 성과:
- 2016년 이세돌 9단과의 대국에서 4승 1패로 승리.
- 2017년 커제 9단과의 대국에서도 승리.
- 의의: 강화학습이 복잡한 비완전 정보 게임에서도 인간을 넘어설 수 있음을 입증.
AlphaZero (2017) - 바둑, 체스, 쇼기 통합 정복
- 기관: DeepMind
- 개요: 기존 게임 규칙만 입력받아, 스스로 연습(Self-Play)만으로 최고의 실력을 달성하는 범용 강화학습 시스템.
- 핵심 기술:
- 기존 AlphaGo Zero 기술을 발전시켜 규칙만으로 스스로 최적 전략을 학습
- 강화학습과 MCTS를 반복 결합하여 최적화
- 성과:
- 바둑, 체스, 쇼기(일본 장기)에서 기존 최고의 프로그램(Stockfish, Elmo 등)을 압도적으로 이김.
- 의의: 지도학습 없이 강화학습만으로도 복잡한 전략 게임을 정복할 수 있음을 보여줌.
OpenAI Five (2018) - Dota 2 도전
- 기관: OpenAI
- 개요: 복잡한 실시간 팀 전략 게임인 Dota 2에서 인간 프로팀과 대등한 실력을 갖춘 인공지능.
- 핵심 기술:
- 대규모 병렬 환경에서 수백만 게임을 자가 대전(Self-Play)
- Proximal Policy Optimization(PPO) 등 정책 기반 강화학습 기법 활용
- 성과:
- 2018년, 국제 프로팀과의 경기에서 승리.
- 의의: 실시간, 다인 협동과 복잡한 전략을 요구하는 게임에서도 강화학습이 뛰어난 성과를 낼 수 있음을 입증.
AlphaStar (2019) - StarCraft II 정복
- 기관: DeepMind
- 개요: 복잡한 실시간 전략 게임 StarCraft II에서 인간 프로를 능가한 인공지능.
- 핵심 기술:
- 대규모 데이터로 사전 학습 후, 자가 대전을 통한 강화학습.
- 다양한 스타일의 에이전트를 병렬 학습(Multi-Agent RL)
- 성과:
- 인간 프로 수준(MMR 기준 99.8% 상위권)의 경기력을 달성.
- 의의: 고차원적 전략, 장기 계획, 복잡한 상황 판단에서도 강화학습이 실질적인 성공을 거둘 수 있음을 보여줌.
주요 게임 분야에서 강화학습 기술 발전 사례별 심화 비교
| 사례 | 연도 | 주요 알고리즘/기술 | 특징 및 발전 포인트 |
| AlphaGo (바둑) |
2016 | 딥러닝 + 강화학습 + 몬테카를로 트리 탐색(MCTS) | 인간 전문가 기보 + 셀프플레이 학습, 정책망과 가치망 사용, 바둑이라는 고도의 복잡성 문제를 해결. |
| AlphaZero (바둑, 체스, 쇼기) |
2017 | 순수 셀프플레이 강화학습 + MCTS | 인간 데이터 없이 스스로 규칙만으로 학습. 범용성 강화, 기존 AlphaGo보다 더 단순한 구조로 고성능 달성. |
| OpenAI Five (도타2) |
2018 | PPO(프로킥스 폴리시 옵티마이제이션) + 팀플레이를 위한 전략적 학습 | 협동(멀티에이전트) 학습, 복잡한 전략과 실시간 환경 대응 능력 강화. 방대한 시뮬레이션을 통해 고속 학습. |
| AlphaStar (스타크래프트 2) |
2019 | 강화학습 + 슈퍼바이즈드 러닝(지도학습) + 셀프플레이 + 커리큘럼 학습 | 실시간 전략 게임(RTS)의 복잡한 전략과 다중 작업 관리 해결. 커리큘럼 기반 학습 도입으로 점진적 수준 향상. |
5. 실제 산업 적용 사례
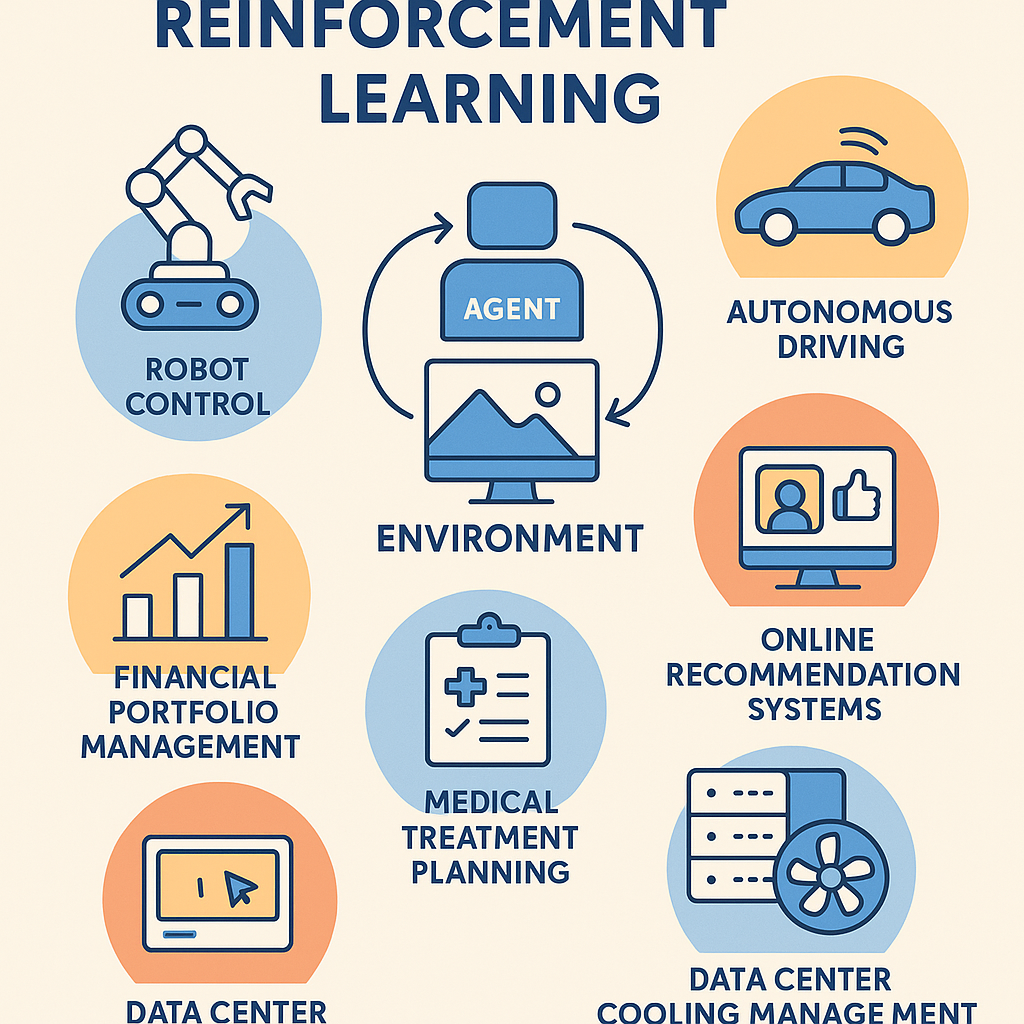
강화학습은 시뮬레이션, 실제 환경, 또는 대규모 데이터를 통해 "경험"을 쌓아가면서 스스로 최적 전략을 찾아가는 기술입니다. 초기에는 게임이나 연구용으로 주로 사용되었지만, 현재는 다양한 산업 영역에서 가시적인 성과를 거두며 실질적 가치를 창출하고 있습니다.
실제로 강화학습은 로봇 제어, 자율 주행, 금융 포트폴리오 관리, 의료 치료 계획, 온라인 추천 시스템, 데이터센터 냉각 관리 등 다양한 산업 현장에서 효과적으로 활용되고 있습니다. 이는 강화학습이 다양한 분야에서 자동화를 이끌 잠재력을 가지고 있음을 시사합니다.
로봇 제어 (Robot Control)
- 활용 내용: 강화학습은 로봇이 복잡한 환경에서 스스로 동작을 학습하도록 합니다. 로봇 팔이 물건을 집거나, 보행 로봇이 균형을 잡고 이동하는 행동을 직접 경험을 통해 개선합니다.
- 대표 사례:
- OpenAI - Robotic Hand (2018): 강화학습을 통해 인간 손가락처럼 로봇 손이 큐브를 조작하는 기술을 성공적으로 개발.
- Boston Dynamics: 로봇 개 'Spot'의 균형 유지, 장애물 회피에 강화학습이 일부 적용.
자율 주행 (Autonomous Driving)
- 활용 내용: 강화학습을 통해 자율주행 차량이 다양한 교통상황에서 최적의 주행 결정을 내릴 수 있도록 학습합니다. 예를 들어 차선 변경, 충돌 회피, 교차로 통과 등의 행동을 개선합니다.
- 대표 사례:
- Wayve: 도로 주행 데이터를 기반으로 강화학습을 통해 실제 도로 환경에서 주행 능력을 학습하는 접근을 시도.
- NVIDIA: 시뮬레이터를 이용해 자율주행 정책을 강화학습으로 훈련하여 안전성을 높이는 연구를 진행.
금융 포트폴리오 관리 (Financial Portfolio Management)
- 활용 내용: 강화학습 에이전트가 투자 자산을 배분하거나 거래 시점을 결정하여 장기 수익을 극대화하는 전략을 스스로 학습합니다.
- 대표 사례:
- J.P. Morgan: 강화학습을 이용해 옵션 거래 전략 최적화를 연구.
- Deep Reinforcement Learning for Portfolio Optimization (논문 사례): 다양한 주식에 대해 투자 비율을 조정하는 에이전트를 개발하여, 전통적 투자전략보다 높은 수익률을 기록.
의료 치료 계획 (Healthcare Treatment Planning)
- 활용 내용: 환자의 치료 과정에서 최적의 투약량, 치료 시기, 방식을 결정하는데 강화학습이 활용됩니다.
- 대표 사례:
- Sepsis 치료 강화학습 연구 (MIT, 2018): 패혈증 환자에게 약물 투여와 수액 조절을 강화학습으로 최적화하여 생존율을 높이는 모델 개발.
- 암 치료 스케줄 최적화: 방사선 치료와 약물 치료의 조합을 강화학습으로 조정하여 부작용 최소화 및 치료 효과 극대화.
온라인 추천 시스템 (Online Recommendation Systems)
- 활용 내용: 사용자 행동에 따라 추천을 즉시 조정하여 사용자 만족도와 클릭률을 극대화합니다. 강화학습은 장기적인 사용자 만족도를 고려하는 점이 특징입니다.
- 대표 사례:
- YouTube 추천 시스템 (Google DeepMind 협업): 사용자의 시청 패턴을 분석하고 장기적인 시청 시간을 최적화하기 위해 강화학습 기반 추천 알고리즘을 연구.
- Alibaba: 강화학습을 이용해 실시간으로 쇼핑 추천을 최적화하여 구매 전환율 상승.
데이터센터 냉각 관리 (Data Center Cooling Optimization)
- 활용 내용: 데이터센터의 에너지 소비를 최소화하면서 온도를 적절히 유지하기 위해 강화학습을 활용합니다.
- 대표 사례:
- Google DeepMind - 데이터센터 냉각 최적화 프로젝트 (2016): 강화학습을 통해 냉각 시스템을 자동 조정하여 에너지 소비를 40% 절감.
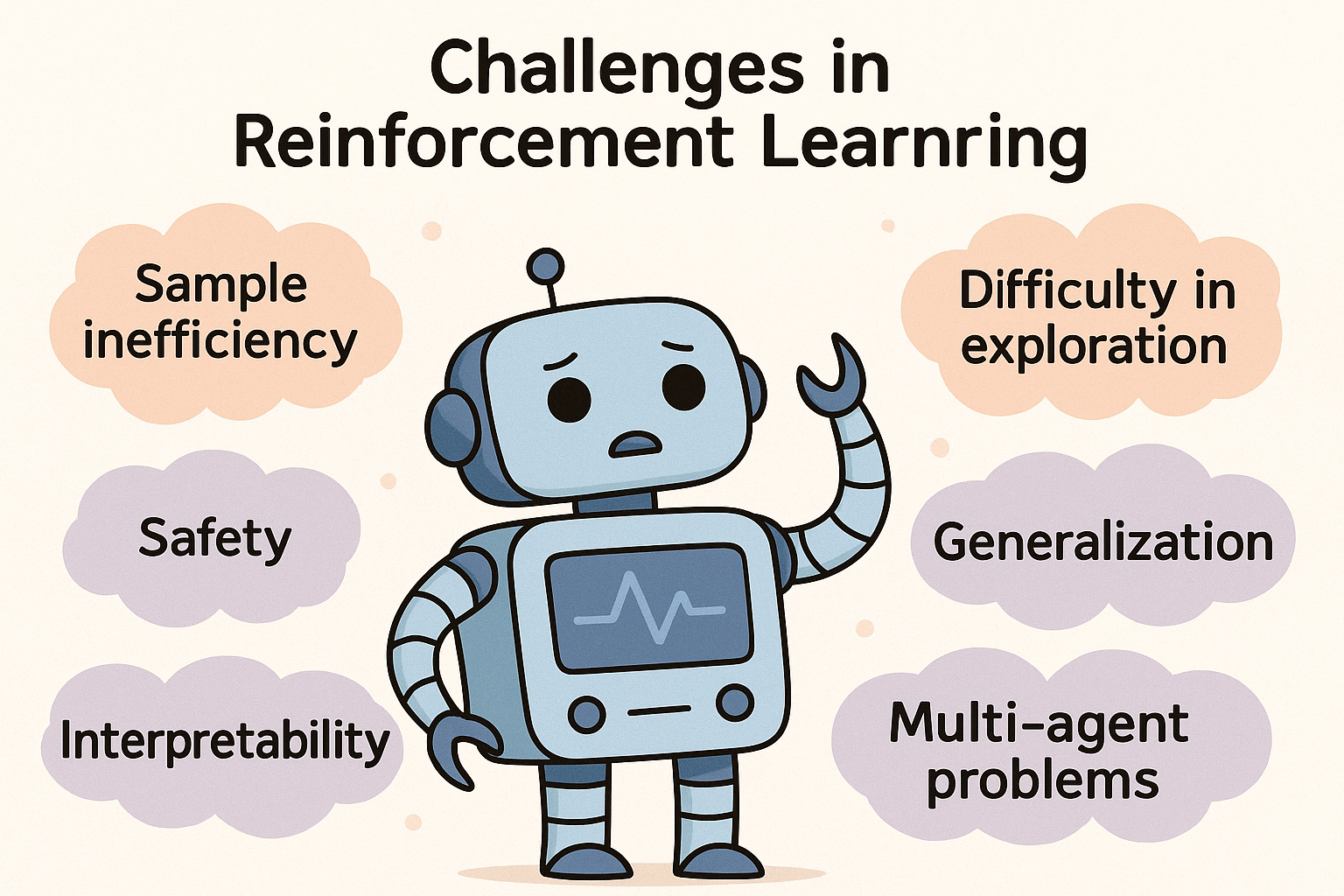
강화학습의 도전 과제
강화학습은 여전히 데이터 비효율성(sample inefficiency), 탐색(exploration)의 어려움, 일반화(generalization) 문제, 안전성(safety) 확보, 해석 가능성(interpretability), 다중 에이전트 문제 등 많은 도전 과제들을 안고 있습니다.
데이터 비효율성 (Sample Inefficiency) : 강화학습은 일반적으로 매우 많은 학습 데이터와 반복 학습을 필요로 합니다. 예를 들어, 게임 하나를 잘 수행하려면 수백만 번의 플레이가 필요할 수 있습니다. 이는 실제 환경에서는 현실적으로 어렵고 비용이 많이 듭니다.
탐색의 어려움 (Exploration) : 강화학습은 새로운 환경에서 좋은 결정을 내리기 위해 충분히 탐색해야 합니다. 하지만 때로는 어떤 행동이 좋은지 알기 어려워 무작정 탐색하다가 오히려 효율성이 떨어질 수 있습니다. 특히 현실 세계에서는 잘못된 탐색이 위험을 초래할 수도 있습니다.
일반화 문제 (Generalization) : 강화학습 에이전트는 특정 환경에서 학습한 내용을 다른 환경에서도 잘 적용할 수 있어야 합니다. 하지만 현실에서는 환경이나 조건이 조금만 바뀌어도 성능이 크게 떨어지는 경우가 많습니다. 이 문제를 해결하기 위해서는 다양한 환경에서 잘 작동하는 방법을 찾아야 합니다.
안전성 확보 (Safety) : 강화학습을 현실 세계에서 사용할 때 가장 중요한 점 중 하나는 안전성입니다. 자율 주행 자동차나 로봇 제어처럼 실제 사람이나 물체와 상호작용하는 경우, 에이전트가 실수로 인해 사고나 피해를 초래하면 안 됩니다. 따라서 에이전트가 항상 안전한 행동을 선택하도록 보장하는 방법이 필요합니다.
해석 가능성 (Interpretability) : 많은 강화학습 모델들은 블랙박스(black box) 형태로, 내부 작동 원리를 명확히 알기 어렵습니다. 에이전트가 왜 그런 결정을 내렸는지 이해하기 어려워, 신뢰도 하락과 윤리적 문제가 발생할 수 있습니다. 따라서 모델이 결정한 이유를 쉽게 설명할 수 있는 기술이 중요합니다.
다중 에이전트 문제 (Multi-Agent Problem) : 현실의 많은 문제들은 여러 에이전트가 동시에 상호작용하는 상황입니다. 예를 들어, 교통 시스템이나 경제 시스템에서는 많은 에이전트들이 각자의 목표를 추구하면서 서로에게 영향을 줍니다. 이러한 상황에서는 각 에이전트가 개별적으로 좋은 성능을 보일 뿐 아니라, 전체 시스템의 성능도 고려해야 합니다.
강화학습의 미래 연구 방향
이러한 도전 과제들을 해결하기 위한 연구가 활발히 진행되고 있으며, 앞으로 강화학습 기술이 더욱 안전하고 효율적으로 발전할 것으로 기대됩니다. 이와 관련된 연구는 앞으로 강화학습의 실용성을 높이는 데 중요한 역할을 할 것입니다.
데이터 효율성 향상 : 강화학습은 많은 시행착오를 통해 학습합니다. 하지만 현실에서는 시행착오를 많이 할 수 없기 때문에, 더 적은 데이터를 사용해 효율적으로 학습하는 방법이 연구되고 있습니다. 이를 위해 기존의 경험을 잘 활용하는 방법(경험 재사용), 모델 기반 강화학습(환경의 동작 방식을 모델링하여 효율적으로 학습), 모방학습(전문가의 행동을 모방해 빠르게 학습)이 활발히 연구되고 있습니다.
탐색 전략 개선 : 탐색(exploration)은 미지의 환경을 더 잘 이해하기 위해 새로운 행동을 시도하는 것입니다. 더 효율적이고 지능적으로 탐색하도록 하기 위해 '호기심 기반 탐색', '내적 동기 탐색', 또는 더 스마트한 탐색 알고리즘이 연구되고 있습니다.
일반화 성능 향상 : 강화학습이 한 환경에서 학습한 것을 다른 비슷한 환경에도 쉽게 적용할 수 있도록 하는 '일반화 능력'이 중요합니다. 이를 위해 도메인 랜덤화(domain randomization), 전이 학습(transfer learning), 메타 학습(meta-learning)과 같은 기법들이 개발되고 있습니다.
안전성 강화 : 강화학습 모델이 현실 세계에 적용될 때는 반드시 안전을 보장해야 합니다. 이 때문에 안전한 정책을 만들 수 있도록 제약 조건을 적용하거나 위험한 행동을 방지하는 알고리즘들이 연구되고 있습니다.
설명 가능성 및 투명성 확보 : 강화학습이 왜 특정 행동을 선택했는지 인간이 이해할 수 있도록 하는 '설명 가능한 강화학습(XRL)'이 중요한 연구 방향입니다. 이를 통해 사람들은 AI의 결정을 더 신뢰하고 AI를 더욱 책임감 있게 사용할 수 있게 됩니다.
다중 에이전트 협력 및 경쟁 : 하나 이상의 에이전트가 협력하거나 경쟁하는 환경에서 효과적으로 학습하는 방법도 중요합니다. 이를 위해 다중 에이전트 강화학습(MARL)이라는 분야가 활발히 연구되고 있으며, 에이전트들이 서로 협력하거나 효율적으로 경쟁할 수 있도록 돕는 방법들이 개발되고 있습니다.