3.2.1 머신러닝의 네 가지 주요 유형 이해하기
머신러닝(Machine Learning, ML)은 인공지능의 한 분야로, 컴퓨터가 명시적으로 프로그래밍되지 않아도 데이터를 통해 학습하고 시간이 지남에 따라 성능을 향상시키는 기술입니다. 머신러닝 알고리즘은 일반적으로 지도학습, 비지도학습, 준지도학습, 강화학습의 4가지 주요 유형으로 분류됩니다. 이 글에서는 각각의 정의, 핵심 개념, 대표 알고리즘, 그리고 금융, 헬스케어, 자연어 처리(NLP) 등 다양한 산업에서의 실제 적용 사례를 중심으로 자세히 살펴봅니다.
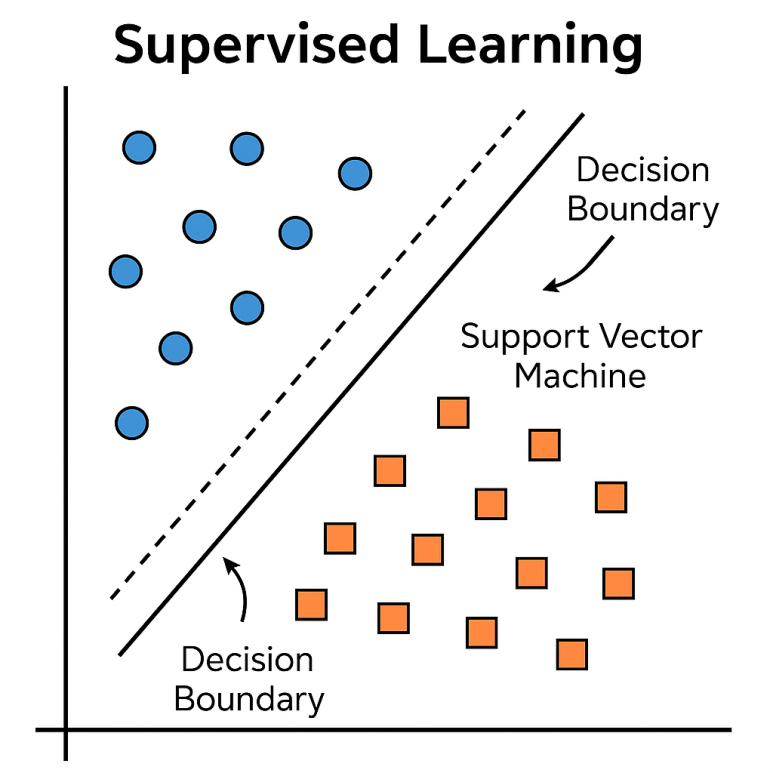
1. 지도학습(Supervised Learning) 📘
🔹 정의
지도학습은 가장 널리 사용되는 머신러닝 방법입니다. 이 학습 방식은 정답(label)이 주어진 데이터를 기반으로 모델을 학습시킵니다. 예를 들어, 이메일 데이터와 해당 이메일이 스팸인지 아닌지를 함께 제공하면, 알고리즘은 이메일의 특성을 바탕으로 스팸 여부를 예측하는 모델을 학습하게 됩니다. 마치 선생님이 정답을 알려주며 학생에게 가르치는 것과 유사합니다.
🔹 핵심 원리
지도학습의 목표는 입력 $x$와 출력 $y$ 간의 관계를 추정하는 함수 $f(x)$를 학습하는 것입니다. 모델은 손실 함수(loss function)를 정의하고, 이 손실을 최소화하는 방향으로 반복적으로 파라미터를 조정하며 학습합니다. 주요 학습 유형으로는 분류(Classification) 와 회귀(Regression) 가 있습니다.
- 분류 예시: 이메일이 스팸인지 아닌지 구분
- 회귀 예시: 주택 가격 예측
🔹 대표 알고리즘
-
- 선형 회귀(Linear Regression), 로지스틱 회귀(Logistic Regression)
- 서포트 벡터 머신(SVM)
- 의사결정나무 및 랜덤 포레스트(Random Forest)
- 인공신경망 및 딥러닝 모델(CNN, RNN 등)
- K-최근접 이웃(K-NN)
AI 활용
🔹 활용 사례
-
- 금융: 대출 상환 여부 예측, 사기 거래 탐지
- 의료: X-ray 이미지를 분석해 폐렴 여부 진단
- NLP: 이메일 스팸 필터링, 감정 분석
- 웹/기술: 추천 시스템, 검색 결과 순위화
🔹 장단점
-
- 높은 예측 정확도
- 라벨 데이터 확보가 어려울 수 있음
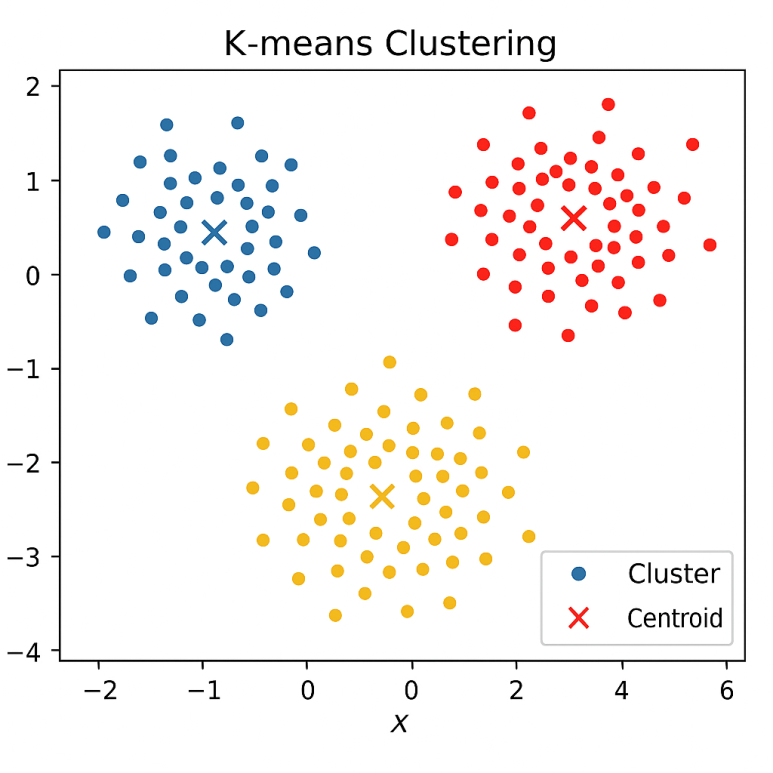
2. 비지도학습(Unsupervised Learning) 🧩
🔹 정의
비지도학습은 라벨이 없는 데이터에서 패턴이나 구조를 스스로 발견하는 학습 방식입니다. 지도학습처럼 정답을 제공하지 않고, 데이터 간의 유사성이나 군집 구조 등을 기반으로 데이터를 이해하려고 합니다.
🔹 핵심 원리
비지도학습은 주로 군집화(Clustering), 차원축소(Dimensionality Reduction), 이상치 탐지(Anomaly Detection), 연관 규칙(Association Rules) 발견을 목표로 합니다.
🔹 대표 기법
-
- 군집화: K-평균, 계층적 군집화, DBSCAN, GMM 등
- 차원축소: PCA, t-SNE, UMAP, 오토인코더
- 이상치 탐지: 밀도기반, 거리기반 이상 탐지
- 연관 규칙: Apriori 알고리즘
AI 활용
🔹 활용 사례
-
- 마케팅/금융: 고객 세분화
- 보안: 이상 거래 탐지
- 생물학/의료: 유전자 표현 군집화
- NLP: 토픽 모델링, 단어 임베딩 학습
🔹 장단점
-
- 대량의 비정형 데이터를 구조화 가능
- 결과 해석에 도메인 지식 필요.
3. 준지도학습(Semi-Supervised Learning) 🌓
🔹 정의
준지도학습은 소량의 라벨 데이터와 대량의 비라벨 데이터를 함께 활용해 모델을 학습시키는 방식입니다. 대부분의 실제 환경에서는 라벨 데이터를 충분히 확보하기 어렵기 때문에, 효율적인 학습 방식으로 주목받고 있습니다.
🔹 핵심 원리
-
- 유사한 데이터는 같은 라벨을 가질 확률이 높다는 가정을 바탕으로 라벨 정보를 확장합니다.
- 예: 몇 개의 라벨만 알고 있어도 주변 비슷한 데이터를 같은 라벨로 분류 가능
🔹 대표 방법
-
- 셀프 트레이닝(Self-Training)
- 코 트레이닝(Co-Training)
- 그래프 기반 라벨 전파(Label Propagation)
- 반지도 SVM, 변분 오토인코더 기반 방법
🔹 활용 사례
-
- 의료 영상: 소수의 라벨 영상으로 대량의 무라벨 영상 학습
- 음성 인식: 일부 음성만 전사하여 전체 음성 데이터를 활용
- 사기 탐지: 소수의 사기 거래 정보로 전체 거래 분석
- 웹페이지 분류: 적은 수의 라벨 웹페이지를 기반으로 전체 분류
🔹 장단점
-
- 적은 라벨로도 높은 성능 가능
- 잘못된 라벨 확산 시 오히려 성능 저하 가능
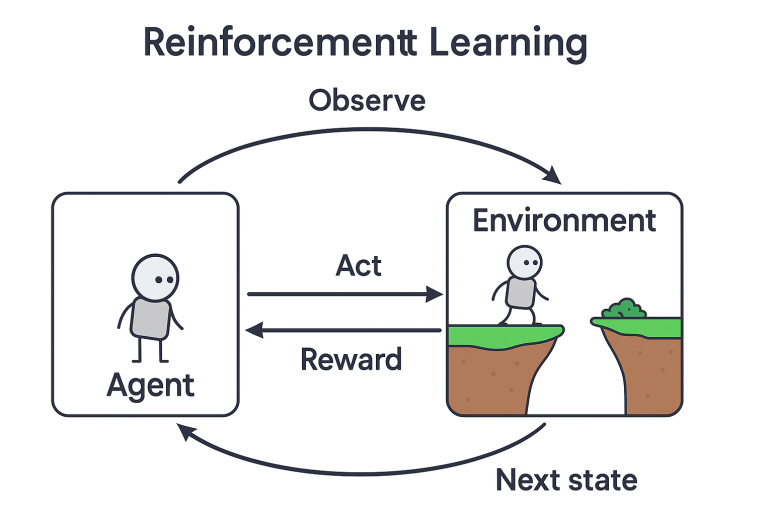
4. 강화학습(Reinforcement Learning) 🕹️
🔹 정의
강화학습은 환경과의 상호작용을 통해 보상(reward)을 최대화하는 학습입니다. 에이전트(agent)는 상태(state)를 관찰하고, 행동(action)을 선택하며, 그 결과로 보상을 받고 다음 상태로 전이합니다. 이 과정에서 최적의 정책(policy) 을 학습합니다.
🔹 핵심 개념
-
- 상태(State): 현재 환경 정보
- 행동(Action): 에이전트의 선택
- 보상(Reward): 결과에 대한 피드백
- 정책(Policy): 상태별 행동 전략
- 가치함수(Value): 상태 혹은 행동의 장기적 보상 기대값
- 탐험 vs 활용: 새로운 행동 탐색 vs 보상 높은 기존 행동 선택
AI 활용
🔹 대표 알고리즘
-
- Q-Learning, SARSA (값 기반)
- Policy Gradient, Actor-Critic (정책 기반)
- DQN, PPO, DDPG 등 딥 강화학습 기법
- 모델 기반 강화학습, 계층 강화학습
🔹 활용 사례
-
- 게임: AlphaGo, Dota2, StarCraft
- 금융: 자동 거래 에이전트 학습
- 로보틱스: 로봇 움직임 최적화
- 자율주행: 안전한 주행 전략 학습
- 헬스케어: 약물 투여 최적화, 환자 치료 경로 결정
- NLP: 텍스트 요약, 챗봇 대화 품질 향상(RLHF)
- 추천시스템: 사용자 반응 기반 추천 최적화
🔹 장단점
-
- 스스로 학습하며 복잡한 전략 도출 가능
- 학습에 많은 시뮬레이션/경험 필요, 안전성 고려 필요
✅ 결론 및 요약
머신러닝은 문제의 특성과 데이터의 유형에 따라 다음과 같이 나뉘며 각각의 장점을 가지고 있습니다:
|
학습 유형
|
라벨 여부
|
대표 과제
|
주요 활용 분야
|
|
지도학습
|
있음
|
분류/회귀
|
의료, 금융, NLP
|
|
비지도학습
|
없음
|
군집화, 차원축소
|
마케팅, 이상 탐지, 탐색
|
|
준지도학습
|
일부 있음
|
라벨 확장
|
의료영상, 사기 탐지
|
|
강화학습
|
보상만 있음
|
순차적 의사결정
|
게임, 로봇, 자율주행
|
📌 실제 문제에서는 여러 학습 방식을 혼합 적용하기도 합니다. 예를 들어 자율주행에서는 이미지 인식을 위해 지도학습, 주행 시나리오 파악을 위해 비지도학습, 운전 전략 학습을 위해 강화학습이 동시에 쓰입니다.